 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEverMemBench: Benchmarking Long-Term Interactive Memory in Large Language Models
Feb 03, 2026Long-term conversational memory is essential for LLM-based assistants, yet existing benchmarks focus on dyadic, single-topic dialogues that fail to capture real-world complexity. We introduce EverMemBench, a benchmark featuring multi-party, multi-group conversations spanning over 1 million tokens with temporally evolving information, cross-topic interleaving, and role-specific personas. EverMemBench evaluates memory systems across three dimensions through 1,000+ QA pairs: fine-grained recall, memory awareness, and user profile understanding. Our evaluation reveals critical limitations: (1) multi-hop reasoning collapses in multi-party settings, with even oracle models achieving only 26%; (2) temporal reasoning remains unsolved, requiring version semantics beyond timestamp matching; (3) memory awareness is bottlenecked by retrieval, where current similarity-based methods fail to bridge the semantic gap between queries and implicitly relevant memories. EverMemBench provides a challenging testbed for developing next-generation memory architectures.
Beyond the Needle's Illusion: Decoupled Evaluation of Evidence Access and Use under Semantic Interference at 326M-Token Scale
Jan 28, 2026Long-context LLM agents must access the right evidence from large environments and use it faithfully. However, the popular Needle-in-a-Haystack (NIAH) evaluation mostly measures benign span localization. The needle is near-unique, and the haystack is largely irrelevant. We introduce EverMemBench-S (EMB-S), an adversarial NIAH-style benchmark built on a 326M-token MemoryBank. While the full MemoryBank spans 326M tokens for retrieval-based (RAG) evaluation, we evaluate native long-context models only at scales that fit within each model's context window (up to 1M tokens in this work) to ensure a fair comparison. EMB-S pairs queries with collision-tested near-miss hard negatives and gold evidence sets spanning one or more documents, validated via human screening and LLM verification. We also propose a decoupled diagnostic protocol that reports evidence access (document-ID localization) separately from end-to-end QA quality under full-context prompting. This enables consistent diagnosis for both native long-context prompting and retrieval pipelines. Across a reference-corpus ladder from domain-isolated 64K contexts to a globally shared 326M-token environment, we observe a clear reality gap. Systems that saturate benign NIAH degrade sharply in evidence access under semantic interference. These results indicate that semantic discrimination, not context length alone, is the dominant bottleneck for long-context memory at scale.
EverMemOS: A Self-Organizing Memory Operating System for Structured Long-Horizon Reasoning
Jan 05, 2026Large Language Models (LLMs) are increasingly deployed as long-term interactive agents, yet their limited context windows make it difficult to sustain coherent behavior over extended interactions. Existing memory systems often store isolated records and retrieve fragments, limiting their ability to consolidate evolving user states and resolve conflicts. We introduce EverMemOS, a self-organizing memory operating system that implements an engram-inspired lifecycle for computational memory. Episodic Trace Formation converts dialogue streams into MemCells that capture episodic traces, atomic facts, and time-bounded Foresight signals. Semantic Consolidation organizes MemCells into thematic MemScenes, distilling stable semantic structures and updating user profiles. Reconstructive Recollection performs MemScene-guided agentic retrieval to compose the necessary and sufficient context for downstream reasoning. Experiments on LoCoMo and LongMemEval show that EverMemOS achieves state-of-the-art performance on memory-augmented reasoning tasks. We further report a profile study on PersonaMem v2 and qualitative case studies illustrating chat-oriented capabilities such as user profiling and Foresight. Code is available at https://github.com/EverMind-AI/EverMemOS.
AAVDiff: Experimental Validation of Enhanced Viability and Diversity in Recombinant Adeno-Associated Virus (AAV) Capsids through Diffusion Generation
Apr 17, 2024Recombinant adeno-associated virus (rAAV) vectors have revolutionized gene therapy, but their broad tropism and suboptimal transduction efficiency limit their clinical applications. To overcome these limitations, researchers have focused on designing and screening capsid libraries to identify improved vectors. However, the large sequence space and limited resources present challenges in identifying viable capsid variants. In this study, we propose an end-to-end diffusion model to generate capsid sequences with enhanced viability. Using publicly available AAV2 data, we generated 38,000 diverse AAV2 viral protein (VP) sequences, and evaluated 8,000 for viral selection. The results attested the superiority of our model compared to traditional methods. Additionally, in the absence of AAV9 capsid data, apart from one wild-type sequence, we used the same model to directly generate a number of viable sequences with up to 9 mutations. we transferred the remaining 30,000 samples to the AAV9 domain. Furthermore, we conducted mutagenesis on AAV9 VP hypervariable regions VI and V, contributing to the continuous improvement of the AAV9 VP sequence. This research represents a significant advancement in the design and functional validation of rAAV vectors, offering innovative solutions to enhance specificity and transduction efficiency in gene therapy applications.
Disjoint Masking with Joint Distillation for Efficient Masked Image Modeling
Dec 31, 2022



Masked image modeling (MIM) has shown great promise for self-supervised learning (SSL) yet been criticized for learning inefficiency. We believe the insufficient utilization of training signals should be responsible. To alleviate this issue, we introduce a conceptually simple yet learning-efficient MIM training scheme, termed Disjoint Masking with Joint Distillation (DMJD). For disjoint masking (DM), we sequentially sample multiple masked views per image in a mini-batch with the disjoint regulation to raise the usage of tokens for reconstruction in each image while keeping the masking rate of each view. For joint distillation (JD), we adopt a dual branch architecture to respectively predict invisible (masked) and visible (unmasked) tokens with superior learning targets. Rooting in orthogonal perspectives for training efficiency improvement, DM and JD cooperatively accelerate the training convergence yet not sacrificing the model generalization ability. Concretely, DM can train ViT with half of the effective training epochs (3.7 times less time-consuming) to report competitive performance. With JD, our DMJD clearly improves the linear probing classification accuracy over ConvMAE by 5.8%. On fine-grained downstream tasks like semantic segmentation, object detection, etc., our DMJD also presents superior generalization compared with state-of-the-art SSL methods. The code and model will be made public at https://github.com/mx-mark/DMJD.
TripleRE: Knowledge Graph Embeddings via Tripled Relation Vectors
Sep 17, 2022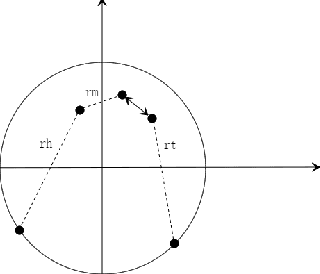
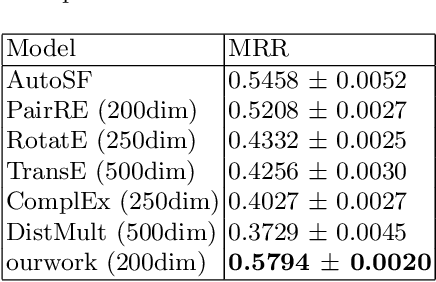

Translation-based knowledge graph embedding has been one of the most important branches for knowledge representation learning since TransE came out. Although many translation-based approaches have achieved some progress in recent years, the performance was still unsatisfactory. This paper proposes a novel knowledge graph embedding method named TripleRE with two versions. The first version of TripleRE creatively divide the relationship vector into three parts. The second version takes advantage of the concept of residual and achieves better performance. In addition, attempts on using NodePiece to encode entities achieved promising results in reducing the parametric size, and solved the problems of scalability. Experiments show that our approach achieved state-of-the-art performance on the large-scale knowledge graph dataset, and competitive performance on other datasets.
StarGraph: A Coarse-to-Fine Representation Method for Large-Scale Knowledge Graph
May 27, 2022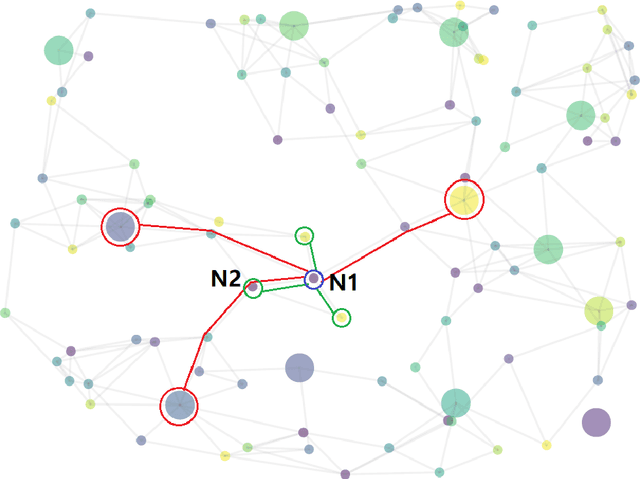
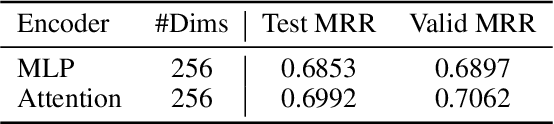
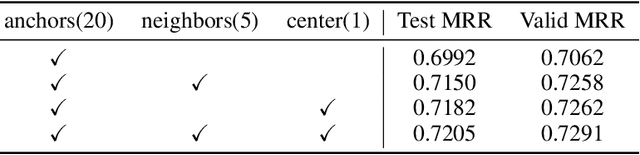
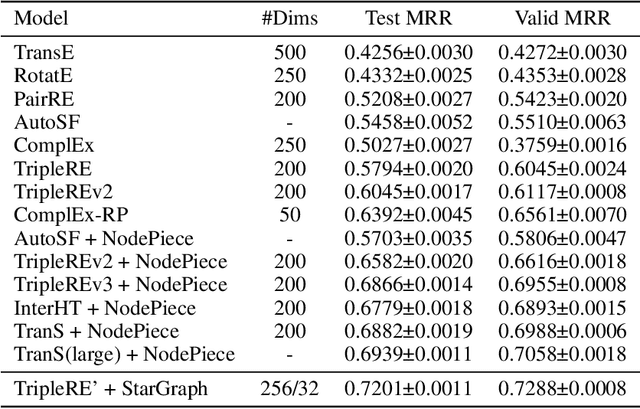
Conventional representation learning algorithms for knowledge graphs (KG) map each entity to a unique embedding vector, ignoring the rich information contained in neighbor entities. We propose a method named StarGraph, which gives a novel way to utilize the neighborhood information for large-scale knowledge graphs to get better entity representations. The core idea is to divide the neighborhood information into different levels for sampling and processing, where the generalized coarse-grained information and unique fine-grained information are combined to generate an efficient subgraph for each node. In addition, a self-attention network is proposed to process the subgraphs and get the entity representations, which are used to replace the entity embeddings in conventional methods. The proposed method achieves the best results on the ogbl-wikikg2 dataset, which validates the effectiveness of it. The code is now available at https://github.com/hzli-ucas/StarGraph
Zero and R2D2: A Large-scale Chinese Cross-modal Benchmark and A Vision-Language Framework
May 08, 2022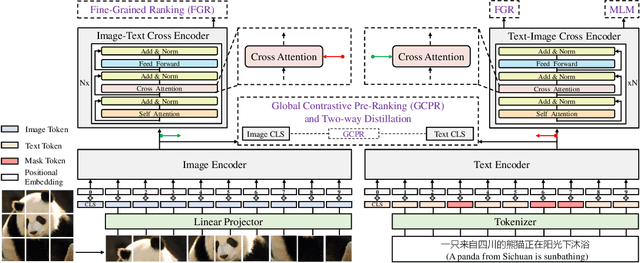
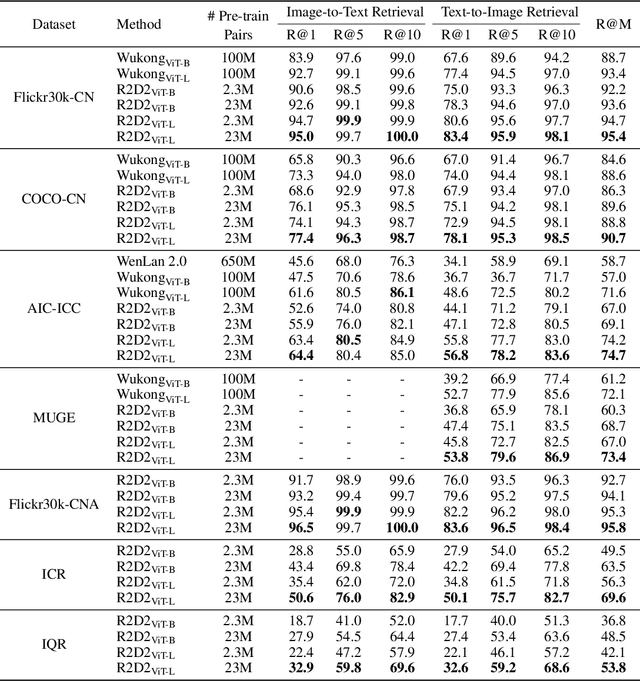

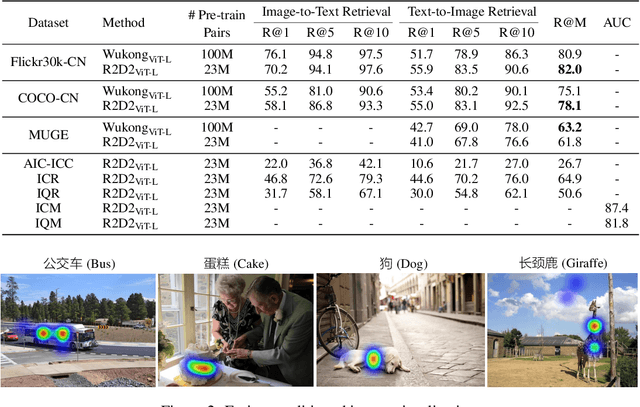
Vision-language pre-training (VLP) relying on large-scale pre-training datasets has shown premier performance on various downstream tasks. In this sense, a complete and fair benchmark (i.e., including large-scale pre-training datasets and a variety of downstream datasets) is essential for VLP. But how to construct such a benchmark in Chinese remains a critical problem. To this end, we develop a large-scale Chinese cross-modal benchmark called Zero for AI researchers to fairly compare VLP models. We release two pre-training datasets and five fine-tuning datasets for downstream tasks. Furthermore, we propose a novel pre-training framework of pre-Ranking + Ranking for cross-modal learning. Specifically, we apply global contrastive pre-ranking to learn the individual representations of images and Chinese texts, respectively. We then fuse the representations in a fine-grained ranking manner via an image-text cross encoder and a text-image cross encoder. To further enhance the capability of the model, we propose a two-way distillation strategy consisting of target-guided Distillation and feature-guided Distillation. For simplicity, we call our model R2D2. We achieve state-of-the-art performance on four public cross-modal datasets and our five downstream datasets. The datasets, models and codes will be made available.
WaBERT: A Low-resource End-to-end Model for Spoken Language Understanding and Speech-to-BERT Alignment
Apr 22, 2022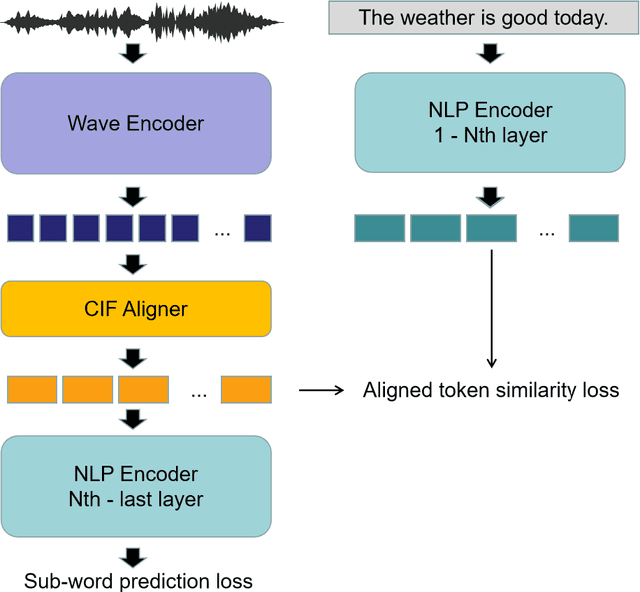


Historically lower-level tasks such as automatic speech recognition (ASR) and speaker identification are the main focus in the speech field. Interest has been growing in higher-level spoken language understanding (SLU) tasks recently, like sentiment analysis (SA). However, improving performances on SLU tasks remains a big challenge. Basically, there are two main methods for SLU tasks: (1) Two-stage method, which uses a speech model to transfer speech to text, then uses a language model to get the results of downstream tasks; (2) One-stage method, which just fine-tunes a pre-trained speech model to fit in the downstream tasks. The first method loses emotional cues such as intonation, and causes recognition errors during ASR process, and the second one lacks necessary language knowledge. In this paper, we propose the Wave BERT (WaBERT), a novel end-to-end model combining the speech model and the language model for SLU tasks. WaBERT is based on the pre-trained speech and language model, hence training from scratch is not needed. We also set most parameters of WaBERT frozen during training. By introducing WaBERT, audio-specific information and language knowledge are integrated in the short-time and low-resource training process to improve results on the dev dataset of SLUE SA tasks by 1.15% of recall score and 0.82% of F1 score. Additionally, we modify the serial Continuous Integrate-and-Fire (CIF) mechanism to achieve the monotonic alignment between the speech and text modalities.
The 2nd Anti-UAV Workshop & Challenge: Methods and Results
Aug 25, 2021

The 2nd Anti-UAV Workshop \& Challenge aims to encourage research in developing novel and accurate methods for multi-scale object tracking. The Anti-UAV dataset used for the Anti-UAV Challenge has been publicly released. There are two subsets in the dataset, $i.e.$, the test-dev subset and test-challenge subset. Both subsets consist of 140 thermal infrared video sequences, spanning multiple occurrences of multi-scale UAVs. Around 24 participating teams from the globe competed in the 2nd Anti-UAV Challenge. In this paper, we provide a brief summary of the 2nd Anti-UAV Workshop \& Challenge including brief introductions to the top three methods.The submission leaderboard will be reopened for researchers that are interested in the Anti-UAV challenge. The benchmark dataset and other information can be found at: https://anti-uav.github.io/.